
NFD40: Scale-Across, Vendor Gravity, and the Elephant out of the Room
Networking Field Day 40 took place April 8-10, 2026, in Silicon Valley, and the schedule gave us something you do not see every week: Nokia, Cisco, and Arista all presenting their networking for AI stories in the same event. Nokia opened the event on April 8, Cisco followed later that day, and Arista presented on April 9. For a networking nerd, this was not quite the Super Bowl, but it was at least a very respectable conference championship weekend. (Tech Field Day) I just hope they all had fun.
The theme was obvious: Networking for AI is now a full-contact sport.
All players came ready to explain how they are building the networks behind AI infrastructure. They talked about silicon, systems, optics, congestion, determinism, job completion time, validated designs, operations, and all the other things that make network engineers nod thoughtfully while quietly wondering how many different CLIs will be required to make this real.
And then there was NVIDIA. NVIDIA was not a formal NFD40 presenter. There was no NVIDIA session on the agenda. No NVIDIA speaker walked to the front of the room. But NVIDIA was absolutely present. They were the presenter that did not need a badge, a session slot, or a clicker. They just floated above the room like a very expensive GPU-shaped sun, exerting gravitational pull on everyone’s vocabulary.
Which brings us to the new phrase of the week: scale-across.
We know scale-up and scale-out, but scale-across was new for me. I do not know whether everyone received the same NVIDIA vocabulary memo, but it certainly felt like the industry had been assigned homework and everyone turned in the same essay. To be clear, the terms are definitely useful. Scale-up is the tight, high-speed interconnect inside a system or rack. Scale-out connects systems into a larger AI cluster inside a data center (East-West traffic). Scale-across connects AI infrastructure across data centers - Far East to Far West, if you will. Nokia restated these as GPU-to-GPU inside a system, system-to-system inside a data center, and DC-to-DC over farther distances.
Scale-across matters because AI infrastructure is running into practical limits. At some point, a single building runs out of power, space, cooling, or patience. The answer is not simply “build a bigger leaf-spine fabric and add more optimism.” The answer increasingly involves connecting multiple facilities and making them behave like parts of a larger AI infrastructure system. Cisco called out scale-across as an emerging third pillar for geographically distributed AI factories, with requirements around long-distance connectivity, deeper buffers, encryption, and coherent optics.
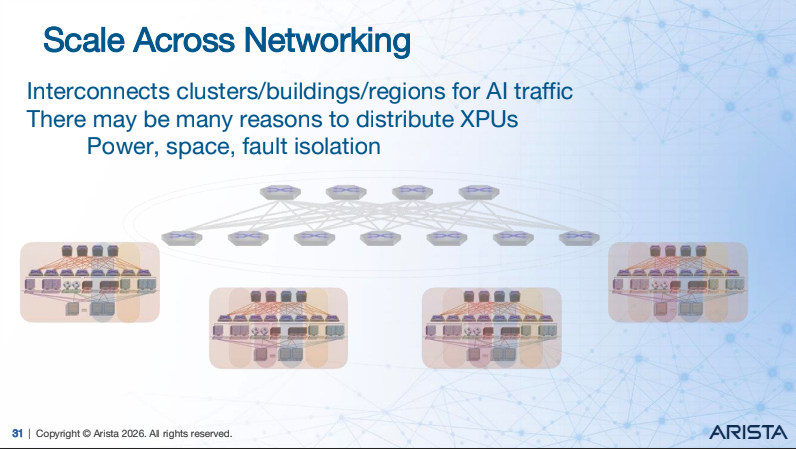
From Arista’s presentation at Network Field Day 40
Arista framed the problem in terms of specific types of networks for GPU clusters: front-end, scale-up, scale-out, and scale-across. Their scale-out story was about connecting racks of XPUs into a cluster. Their scale-across story, which is you can see displayed in the screenshot on the left, was about connecting distributed clusters to increase scale. That framing helps separate the network problems that often get smashed together under the generic label of “AI networking,” which is roughly as precise as saying “cloud” and hoping nobody asks a follow-up question.
The Arista presentation also stood out in that they clearly called out that the network matters to AI performance. They claimed Arista networks for AI can deliver up to 44% faster job completion time, consume less power, and provide more insight. That is the kind of claim operators should pay attention to, not because any vendor slide should be swallowed whole, but because job completion time is the language AI infrastructure operators care about. Network performance is no longer just a nice graph in a dashboard. It is part of the ops and ROI equations.

From Cisco’s presentation at Network Field Day 40
Cisco talked about their integrated foundation: silicon, systems, optics, software, and operating model. They provided pre-briefing material that spelled out Cisco Silicon One, Nexus 9000 systems, Cisco optics, NX-OS, ACI, SONiC, NVIDIA Spectrum-X Ethernet, security, and observability. Cisco also dug into silicon differences, including P-series silicon for scale-across with line-rate encryption, larger tables, deep buffering, and programmable pipelines.
(On the right you can see a couple example switching platforms designed with AI workloads in mind.)
Cisco remains a stalwart in data center networking. That is not in question. Cisco’s enterprise DNA (not DNA Center, now Catalyst Center) comes through clearly. Enterprises will need AI infrastructure too, but the center of gravity in this specific conversation feels more like large-scale AI data centers and neocloud providers. In that space, Arista and Nokia both sounded very focused.
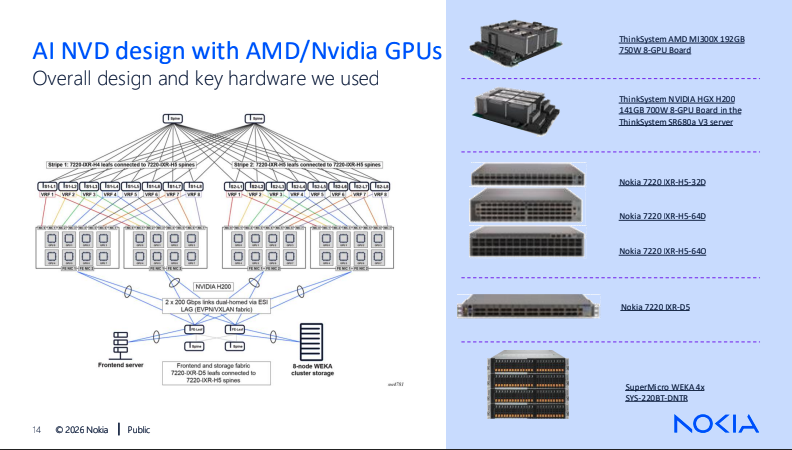
From Nokia’s presentation at Network Field Day 40
Nokia was the pleasant reminder that engineering culture still matters. Nokia does not always talk loudly enough about its engineering excellence, but it should. Their NFD40 presentation leaned into reliability, AI-era traffic patterns, and validated designs including architecture and specific platforms, which you can see in the image on the left.
Nokia characterized AI training as requiring lossless, resilient, reliable networks with congestion control, and AI inferencing as needing high performance, reliability, and low latency. They also described Nokia Validated Designs as prescriptive, tested design foundations using Nokia hardware, SRLinux, and EDA.
That matters because real operators do not run PowerPoint. They run networks. Usually at inconvenient times. Often while someone important is asking why the expensive thing is not doing the expensive thing.
This is where my Total Network Operations bias kicks in. TNOps exists because NetOps does not get enough attention, and because better networks require investment in people, process, and technology. AI networking makes that point even more urgent.
If the network is now tied directly to GPU utilization, training duration, inference latency, and customer-visible outcomes, then operational maturity is not a nice-to-have. It is part of the product.
The optics discussion was another highlight. CPO, LPO, XPO, and traditional pluggables are now part of the AI networking ecosystem. This is where the industry conversation gets especially interesting because NVIDIA’s push toward co-packaged optics could reshape demand for traditional pluggables. We are watching this closely.
Arista’s XPO proposal makes sense because it tries to improve density without throwing operational sanity out the window. I like the idea of not having to RMA an entire switch because one port has a bad day. We have all had bad days. We do not all require a full chassis replacement, even if it’s just a pizza box.
Arista acknowledged that customers will need both pluggable and co-packaged approaches, and they contrasted XPO and CPO across reach, density, power, cost, and failure models. Their argument was that XPO can cover a broader range of scale-up, scale-out, and scale-across use cases, while CPO is more constrained today. That operational flexibility is important. Density is great, but replaceability is the kind of boring feature that becomes exciting at 2:00 a.m. And if you have to do anything to an AI cluster at 2:00 a.m., boring is a superpower.
The NVIDIA relationship question was unavoidable. Cisco has been explicitly calling out NVIDIA Spectrum-X Ethernet in the stack since February 2025. Nokia did not reference their NVIDIA relationship directly, but they secured a $1B investment from NVIDIA not long ago, and their recent stock performance is a very positive sign for them in the AI networking ecosystem. Arista’s response to questions around NVIDIA was humble and smart.
When asked about competing with versus cooperating with NVIDIA, Arista thanked NVIDIA, acknowledged that NVIDIA helped unlock the generative AI networking market, and then explained where Arista believes it can bring differentiated networking value. This was one of my favorite answers of the week. It avoided the two worst options: pretending NVIDIA does not matter, or acting like every other vendor should just report to Jensen by Monday morning. Additionally, the presentation by Tom Emmons of Arista showed their commitment to and understanding of developments in Ultra Ethernet.
The broader takeaway from NFD40 is that AI networking is not just faster Ethernet with better bells and whistles. It is changing how data centers are designed, how optical strategies are evaluated, how operations teams need to think, and how vendors position themselves. Scale-up, scale-out, and scale-across may sound like vocabulary from an industry flashcard deck, but the architectural shift underneath is real.
Cisco has the integrated stack and a long data center track record. Arista has strong traction in large-scale AI networking, a compelling EOS/CloudVision story, and a serious optics strategy. Nokia has a credible and disciplined engineering-led approach that deserves more attention, especially as AI networks move from experimental clusters to infrastructure people must actually operate.
And NVIDIA? NVIDIA did not present at NFD40. Except, of course, it kind of did. It presented through everyone else’s vocabulary, architecture diagrams, partnership slides, and strategic positioning. The most influential presenter in the room was the one that was not in the room.
Welcome to AI networking. The race is on, the vocabulary is evolving, and the network operators will be the ones who have to make all of this work after the slides are over. It’s time for you to dig in on networking for AI; the developments and decisions being made here are going to impact networking well beyond the AI factory.