
How the GPU Became the Foundation of Modern Artificial Intelligence
A Processor Born From Graphics
In the early years of personal computing, the computer screen was not the demanding environment we know today. Graphics were simple, limited to basic shapes, low-resolution images, and rudimentary color palettes. One processor, the central processing unit, or CPU, handled everything. Early operating systems and applications were designed around this single-processor model, where a general-purpose chip was responsible for every computational task. It executed programs, managed memory, processed user input, and rendered visuals to the display. For a time, that was enough.
But as software evolved through the late 1980s and ‘90s, expectations around visual computing evolved with it. Video games, computer-aided design tools, and digital animation pushed computers toward increasingly realistic visual experiences. Developers wanted smooth motion, dynamic lighting, and immersive 3-D environments rendered in real time. Achieving this required an extraordinary number of mathematical calculations every second.
The CPU, designed as a general-purpose problem solver, struggled under the increasing load.
Rendering a 3D scene involves transforming thousands (eventually millions) of points in space, calculating lighting interactions, mapping textures onto surfaces, and determining the color of every pixel on the screen dozens of times per second. These calculations are repetitive and highly parallel, but CPUs were optimized for sequential logic and flexibility rather than repetition at scale. So, the industry responded with specialization.
During the 1990s, companies such as NVIDIA and ATI Technologies (later acquired by AMD) began building dedicated graphics accelerators, or in other words, hardware designed specifically to handle rendering workloads. In 1999, NVIDIA introduced the GeForce 256a chip which the company described as the world’s first “Graphics Processing Unit”, or GPU. Unlike earlier graphics cards, it integrated transform and lighting calculations directly on the chip, meaning the CPU no longer needed to perform geometry computations for 3D scenes. At the time, the goal was straightforward: enable better games and more detailed 3D graphics.

Understanding the GPU
A GPU differs fundamentally from a CPU not just in speed, but in design philosophy.
A CPU is designed to execute complex instructions quickly and adapt to changing tasks. It contains a relatively small number of powerful cores optimized for low latency, complex control flow, and rapid context switching. This makes it ideal for operating systems, application logic, and tasks that need branching or unpredictability.
A GPU, on the other hand, is optimized for throughput rather than latency. Instead of a few powerful cores, it contains thousands of smaller ones designed to perform the same operation simultaneously across large datasets. Its strength lies in parallelism, which means doing many simple calculations at once rather than a few complicated ones sequentially.
This architecture makes perfect sense for graphics. Each pixel in an image can be computed independently from its neighbors. If millions of pixels need to be calculated simultaneously, distributing the workload across thousands of cores dramatically accelerates rendering.
The GPU became, in essence, a machine built for large-scale mathematical repetition, and that turned out to be exactly what artificial intelligence needed.
Graphics and Neural Network Math
At their core, both graphics rendering and machine learning rely on the same mathematical foundation: linear algebra.
Rendering a 3D object involves multiplying matrices that represent rotation, scaling, and perspective transformations.Vector operations determine lighting and shading effects. Animation pipelines repeatedly apply mathematical transformations across massive datasets.
Neural networks operate similarly. Training a model involves multiplying large matrices representing weights and inputs, adjusting parameters through gradient descent, and repeating this process billions or trillions of times.
For decades, these two domains existed independently. Graphics engineers optimized hardware for visual computation, while AI researchers struggled with limited computational resources.
Interestingly, the bridge between them formed almost accidentally.
In 2006, NVIDIA introduced CUDA, a programming platform that allowed developers to use GPUs for general-purpose computing rather than graphics. Suddenly, researchers could harness graphics hardware for scientific computation, simulations, and machine learning experiments.
When deep learning began gaining momentum in the early 2010s, researchers discovered that GPUs dramatically accelerated neural network training. Tasks that once took weeks on CPUs could be completed in days or hours.
A pivotal moment came in 2012, when deep learning models trained using GPUs achieved breakthrough performance in image recognition competitions. The results showed that neural networks could scale, but only if supported by massively parallel hardware.
The GPU, originally built for video games, became the engine of modern AI development.
Different Tools for Different Problems
To understand why GPUs transformed artificial intelligence, it helps to compare them directly with CPUs.
The CPU remains the brain of a computer system. It manages operations systems, coordinates program execution, and orchestrates workflows. Its design prioritizes low latency and flexibility. When a program requires decision-making, branching logic, or irregular computation, CPUs perform exceptionally well.
GPUs, by contrast, are optimized for data-parallel workloads. Notice in the side-by-side graphic below in which we can see the conceptual difference of CPU and GPU architectures. On the right, we can see the many individual processors operating in parallel each performing a single task. They sacrifice flexibility for scale, enabling thousands of identical operations to occur simultaneously, making them perfect for workloads involving repeated mathematical operations across large datasets.
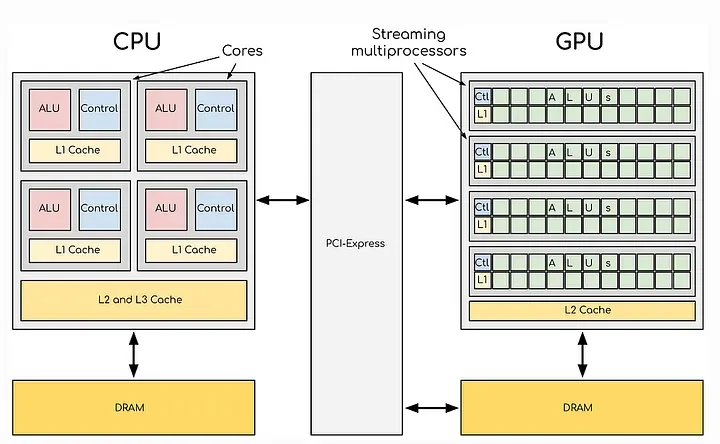
Image: CPU vs. GPU — Core Architectural Differences https://medium.com/@rohithreddy66666/decoding-cpu-vs-gpu-a-detailed-exploration-of-nvidia-and- amd-gpu-architectures-e09ebfb594ed)
In the next image below, adapted from the CUDA C Programming Guide (v.9.1), we can see the raw computational speed of several different CPU and GPU models. This shows us the computational potential of GPUs, which is measured in billions of floating-point operations per second (Gflop/s).
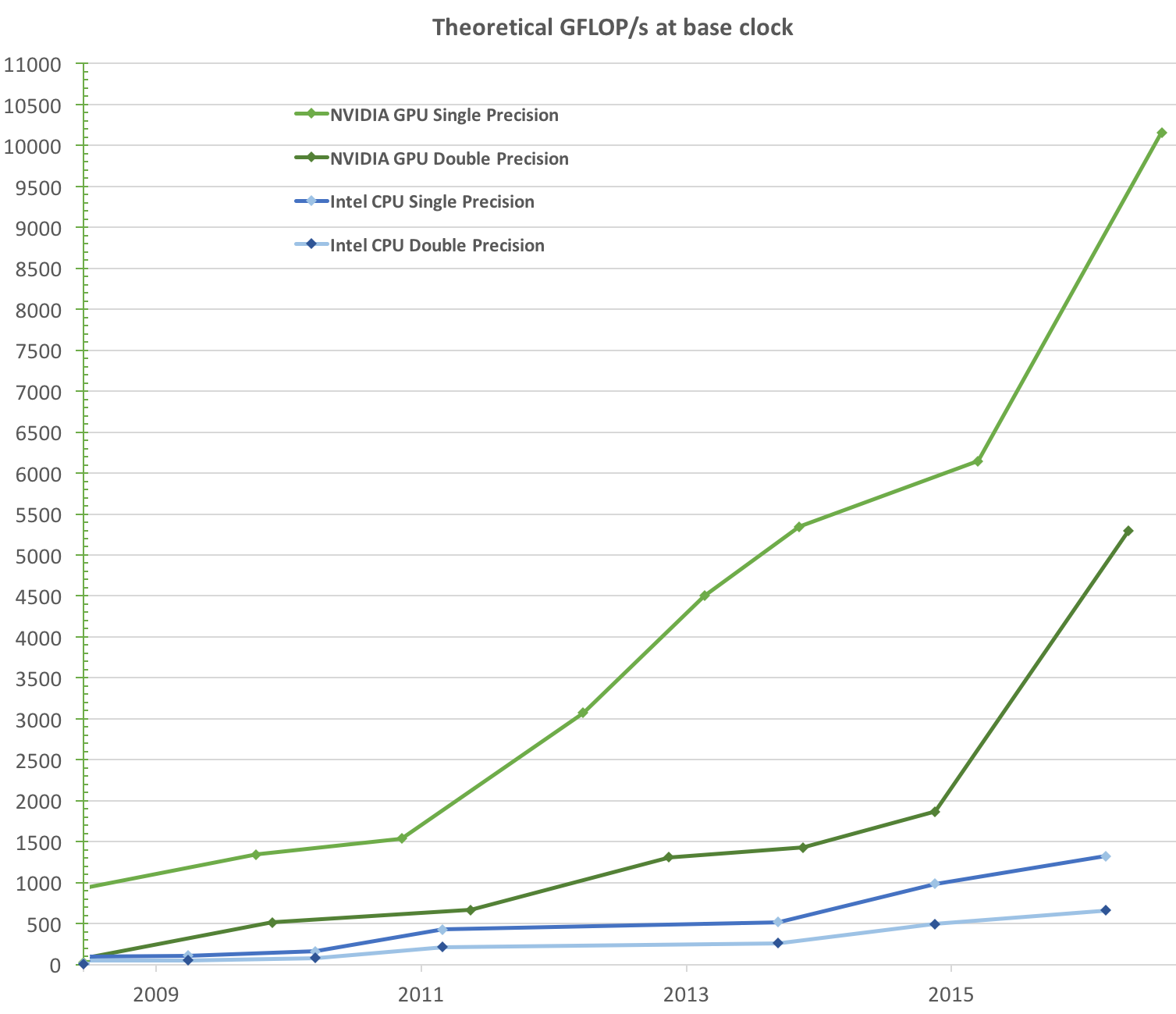
AI training fits perfectly into the GPU model. Each training step applies the same mathematical operations across enormous volumes of data. Rather than solving one problem quickly, GPUs solve millions of similar problems at once, though it’s important to note that modern AI systems actually rely on both processors together: CPUs orchestrate tasks and manage data pipelines, while GPUs perform the heavy numerical computation.
The Rise of Large Language Models
Large language models represent one of the most computationally demanding workloads of our time. These models, based on transformer architectures, process language by converting text into numerical vectors and passing them through layers of matrix operations. Each layer performs massive multiplications involving billions of parameters. Training models requires repeating these operations across vast datasets containing books, articles, web text, and in several cases the content of the entire public internet.
Without GPUs, such models would be practically impossible to train within reasonable time or cost constraints. What once rendered virtual landscapes now computes attention mechanisms and linguistic relationships across human language itself.
The GPU did not merely accelerate AI; it enabled its modern form.
The Emergence of TPUs
As artificial intelligence matured, hardware designers wondered: if GPUs work so well for AI, what would happen if we built chips specifically for neural networks?
This question led to the development of the Tensor Processing Unit (TPU) by Google, which we can see in the image below.
In the image on the right we see Google’s first Tensor Processing Unit (TPU) on a printed circuit board (left); and we see TPUs deployed in a Google datacenter (right)

Unlike GPUs, which evolved from graphics hardware, TPUs were designed from the beginning for tensor operations, which are the matrix computations at the heart of machine learning. TPUs use specialized circuits optimized for large-scale matrix multiplication and reduced-precision arithmetic, allowing them to perform AI workloads with exceptional efficiency and energy performance. In large data centers, TPUs can train and run machine learning models at enormous scale while consuming less power per computation than traditional hardware.
CPU vs GPU vs TPU
Each processor type reflects a different philosophy of computing.
The CPU is a generalist — adaptable, flexible, and essential for coordination and system control.
The GPU is a parallel powerhouse — versatile enough for graphics, simulation, and AI training while delivering massive computational throughput.
The TPU is a specialist — engineered specifically for neural networks and optimized for efficiency at hyperscale.
Rather than replacing one another, these processors form a layered ecosystem. CPUs manage systems, GPUs provide flexible acceleration, and TPUs push efficiency boundaries in large-scale AI deployments.
Why GPUs Still Dominate AI
Despite the rise of specialized AI hardware, GPUs remain central to modern machine learning for several reasons. Their software ecosystem is mature and widely supported, enabling researchers to experiment freely. Frameworks such as PyTorch and TensorFlow evolved alongside GPU computing, creating a deep integration between hardware and software.
Equally important, GPUs remain flexible. They can handle simulations, graphics, scientific computing, and AI workloads alike. This adaptability makes them indispensable for research environments where experimentation matters as much as efficiency.
In many ways, GPUs have become the universal accelerator of modern computing.
From Pixels to Intelligence
The evolution of the GPU illustrates how technological revolutions often emerge from unexpected origins. Engineers originally designed GPUs to render faster graphics for video games. Their goal was to compute millions of pixels simultaneously in order to create immersive digital worlds. In solving that problem, they unknowingly created hardware perfectly suited for a future defined by data and learning.
Today, GPUs power large language models, scientific discovery, climate simulations, and medical research. They help machines interpret language, generate ideas, and assist human creativity at unprecedented scale.
What began as a tool for rendering imaginary worlds has become the infrastructure for modeling reality itself. The GPU did not set out to enable artificial intelligence, but in solving the challenge of graphics, it built the foundation for today’s age of intelligence.